Data Access
In xcube, data cubes are raster datasets that are basically a collection of N-dimensional geo-physical variables represented by xarray.Dataset Python objects (see also xcube Dataset Convention). Data cubes may be provided by a variety of sources and may be stored using different data formats. In the simplest case you have a NetCDF file or a Zarr directory in your local filesystem that already represents a data cube. Data cubes may also be stored on AWS S3 or Google Cloud Storage using the Zarr format. Sometimes a set of NetCDF or GeoTIFF files in some storage must first be concatenated to form a data cube. In other cases, data cubes can be generated on-the-fly by suitable requests to some cloud-hosted data API such as the ESA Climate Data Centre or Sentinel Hub.
Data Store Framework
The xcube data store framework provides a simple and consistent Python interface that is used to open xarray.Dataset and other data objects from data stores which abstract away the individual data sources, protocols, formats and hides involved data processing steps. For example, the following two lines open a data cube from the ESA Climate Data Centre comprising the essential climate variable Sea Surface Temperature (SST):
store = new_data_store("cciodp")
cube = store.open_data("esacci.SST.day.L4.SSTdepth.multi-sensor.multi-platform.OSTIA.1-1.r1")
Often, and in the example above, data stores create data cube views on a given data source. That is, the actual data arrays are subdivided into chunks and each chunk is fetched from the source in a “lazy” manner. In such cases, the xarray.Dataset’s variables are backed by Dask arrays. This allows data cubes to be virtually of any size.
Data stores can provide the data using different Python in-memory representations or data types. The most common representation for a data cube is an xarray.Dataset instance, multi-resolution data cubes would be represented as a xcube MultiLevelDataset instance (see also xcube Multi-Level Dataset Convention). Vector data is usually provided as an instance of geopandas.GeoDataFrame.
Data stores can also be writable. All read-only data stores share the same
functional interface and so do writable
data stores. Of course, different data stores will have different
configuration parameters. Also, the parameters passed to the open_data()
method, or respectively the write_data() method, may change based on the
store’s capabilities.
Depending on what is offered by a given data store, also the parameters
passed to the open_data() method may change.
The xcube data store framework is exported from the xcube.core.store package, see also its API reference.
The DataStore abstract base class is the primary user interface for accessing data in xcube. The most important operations of a data store are:
list_data_ids()- enumerate the datasets of a data store by returning their data identifiers;describe_data(data_id)- describe a given dataset in terms of its metadata by returning a specific DataDescriptor, e.g., a DatasetDescriptor;search_data(...)- search for datasets in the data store and return a DataDescriptor iterator;open_data(data_id, ...)- open a given dataset and return, e.g., an xarray.Dataset instance.
The MutableDataStore abstract base class represents a writable data store and extends DataStore by the following operations:
write_data(dataset, data_id, ...)- write a dataset to the data store;delete_data(data_id)- delete a dataset from the data store;
Above, the ellipses ... are used to indicate store-specific parameters
that are passed as keyword-arguments. For a given data store instance,
it is not obvious what are parameters are allowed. Therefore, data stores
provide a programmatic way to describe the allowed parameters for the
operations of a given data store by the means of a parameter schema:
get_open_data_params_schema()- describes parameters ofopen_data();get_search_data_params_schema()- describes parameters ofsearch_data();get_write_data_params_schema()- describes parameters ofwrite_data().
All operations return an instance of a JSON Object Schema. The JSON object’s properties describe the set of allowed and required parameters as well as the type and value range of each parameter. The schemas are also used internally to validate the parameters passed by the user.
xcube comes with a predefined set of writable, filesystem-based data stores. Since data stores are xcube extensions, additional data stores can be added by xcube plugins. The data store framework provides a number of global functions that can be used to access the available data stores:
find_data_store_extensions() -> list[Extension]- get a list of xcube data store extensions;new_data_store(store_id, ...) -> DataStore- instantiate a data store with store-specific parameters;get_data_store_params_schema(store_id) -> Schema- describe the store-specific parameters that must/can be passed tonew_data_store()as JSON Object Schema.
The following example outputs all installed data stores:
from xcube.core.store import find_data_store_extensions
for ex in find_data_store_extensions():
store_id = ex.name
store_md = ex.metadata
print(store_id, "-", store_md.get("description"))
If one of the installed data stores is, e.g. sentinelhub, you could
further introspect its specific parameters and datasets as shown in the
following example:
from xcube.core.store import get_data_store_params_schema
from xcube.core.store import new_data_store
store_schema = get_data_store_params_schema("sentinelhub")
store = new_data_store("sentinelhub",
# The following parameters are specific to the
# "sentinelhub" data store.
# Refer to the store_schema.
client_id="YOURID",
client_secret="YOURSECRET",
num_retries=250,
enable_warnings=True)
data_ids = store.list_data_ids()
# Among others, we find "S2L2A" in data_ids
open_schema = store.get_open_data_params_schema("S2L2A")
cube = store.open_data("S2L2A",
# The following parameters are specific to
# "sentinelhub" datasets, such as "S2L2A".
# Refer to the open_schema.
variable_names=["B03", "B06", "B8A"],
bbox=[9, 53, 20, 62],
spatial_res=0.025,
crs="WGS-84",
time_range=["2022-01-01", "2022-01-05"],
time_period="1D")
Available Data Stores
This sections lists briefly the official data stores available for xcube. We provide the store identifier, list the store parameters, and list the common parameters used to open data cubes, i.e., xarray.Dataset instances.
Note that in some data stores, the open parameters may differ from dataset to dataset depending on the actual dataset layout, coordinate references system or data type. Some data stores may also provide vector data.
For every data store we also provide a dedicated example Notebook that demonstrates its specific usage in examples/notebooks/datastores.
Use list_data_store_ids() to list all data stores available in your current Python environment.
The output depends on the installed xcube plugins.
from xcube.core.store import list_data_store_ids
list_data_store_ids()
Filesystem-based data stores
The following filesystem-based data stores are available in xcube:
"file"for the local filesystem;"s3"for AWS S3 compatible object storage;"abfs"for Azure blob storage;"memory"for mimicking an in-memory filesystem;"https"for https protocols;"ftp"for FTP server;"reference"for read-onlyfsspecreference file systems.
All filesystem-based data store have the following parameters:
root: str- The root directory of the store in the filesystem. Defaults to''.max_depth: int- Maximum directory traversal depth. Defaults to1.read_only: bool- Whether this store is read-only. Defaults toFalse.includes: list[str]- A list of paths to include into the store. May contain wildcards*and?. Defaults toUNDEFINED.excludes: list[str]- A list of paths to exclude from the store. May contain wildcards*and?. Defaults toUNDEFINED.storage_options: dict[str, any]- Filesystem-specific options.
The reference store has the following additional parameters:
refs: list- List of references to use for this instance. Items can be:A path or URL to a reference JSON file, or
A dictionary with:
ref_path: str- Path or URL to the reference file. Required.data_id: str- Optional identifier for the referenced data.data_descriptor: dict- Optional metadata or descriptor.
target_protocol: str- Target Protocol. If not provided, derived from the given path.target_options: str- Additional options for loading reference files.remote_protocol: str- Protocol of the filesystem on which the references. Derived from the first reference with a protocol, if not given. will be evaluated.remote_options: str- Additional options for loadings reference files.max_gap: int- Max byte-range gap allowed when merging concurrent requests.max_block: int- Max size of merged byte ranges.cache_size: int- Max size of LRU cache.
The parameter storage_options is filesystem-specific. Valid
storage_options for all filesystem data stores are:
use_listings_cache: boollistings_expiry_time: floatmax_paths: intskip_instance_cache: boolasynchronous: bool
The following storage_options can be used for the file data store:
auto_mkdirs: bool- Whether, when opening a file, the directory containing it should be created (if it doesn’t already exist).
The following storage_options can be used for the s3 data store:
anon: bool- Whether to anonymously connect to AWS S3.key: str- AWS access key identifier.secret: str- AWS secret access key.token: str- Session token.use_ssl: bool- Whether to use SSL in connections to S3; may be faster without, but insecure. Defaults toTrue.requester_pays: bool- If “RequesterPays” buckets are supported. Defaults toFalse.s3_additional_kwargs: dict- parameters that are used when calling S3 API methods. Typically, used for things like “ServerSideEncryption”.client_kwargs: dict- Parameters for the botocore client.
The following storage_options can be used for the abfs data store:
anon: bool- Whether to anonymously connect to Azure Blob Storage.account_name: str- Azure storage account name.account_key: str- Azure storage account key.connection_string: str- Connection string for Azure blob storage.
The following storage_options can be used for the ftp data store:
host- Remote server name/ipport- FTP Port, min: 0, max: 65535,default: 21username- User’s identifier, if usingpassword- User’s password, if using
All filesystem data stores can open datasets from various data formats. Datasets in Zarr, GeoTIFF / COG, JPEG 2000, or NetCDF format will be provided either by xarray.Dataset or xcube MultiLevelDataset instances. Datasets stored in GeoJSON or ESRI Shapefile will yield geopandas.GeoDataFrame instances.
Common parameters for opening xarray.Dataset instances:
cache_size: int- Defaults toUNDEFINED.group: str- Group path. (a.k.a. path in zarr terminology.). Defaults toUNDEFINED.chunks: dict[str, int | str]- Optional chunk sizes along each dimension. Chunk size values may be None, “auto” or an integer value. Defaults toUNDEFINED.decode_cf: bool- Whether to decode these variables, assuming they were saved according to CF conventions. Defaults toTrue.mask_and_scale: bool- If True, replace array values equal to attribute “_FillValue” with NaN. Use “scale_factor” and “add_offset” attributes to compute actual values.. Defaults toTrue.decode_times: bool- If True, decode times encoded in the standard NetCDF datetime format into datetime objects. Otherwise, leave them encoded as numbers.. Defaults toTrue.decode_coords: bool- If True, decode the “coordinates” attribute to identify coordinates in the resulting dataset. Defaults toTrue.drop_variables: list[str]- List of names of variables to be dropped. Defaults toUNDEFINED.consolidated: bool- Whether to open the store using Zarr’s consolidated metadata capability. Only works for stores that have already been consolidated. Defaults toFalse.log_access: bool- Defaults toFalse.
Copernicus Climate Data Store cds
The data store cds provides datasets of the Copernicus Climate Data Store.
This data store is provided by the xcube plugin xcube-cds.
You can install it using conda install -c conda-forge xcube-cds.
Data store parameters:
cds_api_key: str- User API key for Copernicus Climate Data Store.endpoint_url: str- API endpoint URL.num_retries: int- Defaults to200.normalize_names: bool- Defaults toFalse.
Common parameters for opening xarray.Dataset instances:
bbox: (float, float, float, float)- Bounding box in geographical coordinates.time_range: (str, str)- Time range.variable_names: list[str]- List of names of variables to be included. Defaults to all.spatial_res: float- Spatial resolution. Defaults to0.1.
Copernicus Marine Service cmems
The data store cmems provides datasets of the Copernicus Marine Service.
This data store is provided by the xcube plugin xcube-cmems.
You can install it using conda install -c conda-forge xcube-cmems.
Data store parameters:
cmems_username: str- CMEMS API usernamecmems_password: str- CMEMS API passwordcas_url: str- Defaults to'https://cmems-cas.cls.fr/cas/login'.csw_url: str- Defaults to'https://cmems-catalog-ro.cls.fr/geonetwork/srv/eng/csw-MYOCEAN-CORE-PRODUCTS?'.databases: str- One of['nrt', 'my'].server: str- Defaults to'cmems-du.eu/thredds/dodsC/'.
Common parameters for opening xarray.Dataset instances:
variable_names: list[str]- List of variable names.time_range: [str, str]- Time range.
Copernicus Land Monitoring Service clms
The data store clms provides datasets of the Copernicus Land Monitoring Service.
This data store is provided by the xcube plugin xcube-clms.
You can install it using conda install -c conda-forge xcube-clms.
Data store parameters:
credentials: dict: CLMS API credentials that can be obtained following the steps outlined here. These are the credentials parameters:client_id: str- Required.issued: strprivate_key: str- Required.key_id: strtitle: strtoken_uri: str- Required.user_id: str- Required.
cache_store_id: str- Store ID of cache data store. Defaults tofile.cache_store_params: dict- Store parameters of a filesystem-based data store.
Before opening a specific dataset from CLMS, it’s required to preload the data first. Preloading lets you create data requests ahead of time, which may sit in a queue before being processed. Once processed, the data is downloaded as zip files, unzipped, extracted to a cache, and prepared for use. After this, it can be accessed through the cache data store.
The preload parameters are:
blocking: bool- Switch to make the preloading process blocking or non-blocking. If True, the preloading process blocks the script. Defaults toTrue.silent: bool- Silence the output of Preload API. If True, no preload state output is given. Defaults toFalse.cleanup: bool- Cleanup the download directory before and after the preload job and the cache directory when preload_handle.close() is called. Defaults toTrue.
Its common dataset open parameters for opening xarray.Dataset instances are the same as for the filesystem-based data stores described above.
EOPF Sample Service eopf-zarr
The data store eopf-zarr provides access to the EOPF Sentinel Zarr Samples as an
analysis-ready datacube (ARDC).
This data store is provided by the xcube plugin xcube-eopf.
You can install it using conda install -c conda-forge xcube-eopf.
No data store parameters needed.
Common parameters for opening xarray.Dataset instances:
bbox: ?[float|int, float|int, float|int, float|int]?- Bounding box [”west”, “south”, “est”, “north”] in CRS coordinates.time_range: [str, str]- Temporal extent [”YYYY-MM-DD”, “YYYY-MM-DD”].spatial_res: int|float- Spatial resolution in meter of degree (depending on the CRS).crs: str- Coordinate reference system (e.g."EPSG:4326").variables: ?str | list[str]?- Variables to include in the dataset. Can be a name or regex pattern or iterable of the latter.query: Any (not specified)- Additional query options for filtering STAC Items by properties. See STAC Query Extension for details.
ESA Climate Data Centre (ESA CCI) cciodp, ccizarr, esa-cci-kc
Three data stores are provided by the xcube plugin xcube-cci.
You can install the plugin using conda install -c conda-forge xcube-cci.
cciodp
The data store cciodp provides the datasets of
the ESA Climate Data Centre.
Data store parameters:
endpoint_url: str- Defaults to'https://archive.opensearch.ceda.ac.uk/opensearch/request'.endpoint_description_url: str- Defaults to'https://archive.opensearch.ceda.ac.uk/opensearch/description.xml?parentIdentifier=cci'.enable_warnings: bool- Whether to output warnings. Defaults toFalse.num_retries: int- Number of retries when requesting data fails. Defaults to200.retry_backoff_max: int- Defaults to40.retry_backoff_base: float- Defaults to1.001.
Common parameters for opening xarray.Dataset instances:
variable_names: list[str]- List of variable names. Defaults to all.bbox: (float, float, float, float)- Bounding box in geographical coordinates.time_range: (str, str)- Time range.normalize_data: bool- Whether to normalize and sanitize the data. Defaults toTrue.
ccizarr
A subset of the datasets of the cciodp store have been made available
using the Zarr format using the data store ccizarr. It provides
much better data access performance.
It has no dedicated data store parameters.
Its common dataset open parameters for opening xarray.Dataset instances are the same as for the filesystem-based data stores described above.
esa-cci-kc
The data store esa-cci-kc accesses datasets that are offered by the Open Data Portal
via the references format.
Data store parameters are the same as for the filesystem-based reference store.
Its common dataset open parameters for opening xarray.Dataset instances are the same as for the filesystem-based data stores described above.
ESA SMOS smos
The data store smos provides L2C datasets of the ESA Soil Moisture and Ocean Salinity
mission.
This data store is provided by the xcube plugin xcube-smos. You can install it using
conda install -c conda-forge xcube-smos.
Data store parameters:
source_path: str- Path or URL into SMOS archive filesystem.source_protocol: str: Protocol name for the SMOS archive filesystem.source_storage_options: dict: Storage options for the SMOS archive filesystem. See fsspec documentation for specific filesystems. Any option can be overriden by passing it as additional data store parameter.cache_path: str: Path to local cache directory. Must be given, if file caching is desired.xarray_kwargs: dict: Extra keyword arguments accepted byxarray.open_dataset.
Common parameters for opening xarray.Dataset instances:
time_range: (str, str)- Time range given as pair of start and stop dates. Format:YYYY-MM-DD. Required.bbox: (float, float, float, float)- Bounding box in geographical coordinates.res_level: int- Spatial resolution level in the range 0 to 4. Zero refers to the max resolution of 0.0439453125 degrees.
Global Ecosystem Dynamics Investigation gedidb
The data store gedidb provides access to Global Ecosystem Dynamics Investigation
(GEDI) data. The store is developed using the API from gedidb which is licensed under
European Union Public License 1.2.
This data store is provided by the xcube plugin xcube-gedidb. Due to the
unavailability of gedidb as a conda package, xcube-gedidb is packaged via PyPi.
To install it, please make sure you have an activated conda environment created from the
environment.yml,
and then do pip install xcube-gedi.
It has no dedicated data store parameters.
This data store can be requested to open the datasets in one of two ways:
request all available data within a bounding box by specifying a
bboxin theopen_datamethod.request all available data around a given point by specifying a
pointin theopen_datamethod.
Parameters for opening xarray.Dataset instances:
Either
bbox: (float, float, float, float)- A bounding box in the form of(xmin, ymin, xmax, ymax). Required.
Or
point: (float, float)- Reference point for nearest query. Requirednum_shots: int- Number of shots to retrieve. Defaults to10.radius: float- Radius in degrees around the point Defaults to0.1.
Common:
time_range: (str, str)- Time range. Required.variables: list[str]- List of variables to retrieve from the database.
ICOS Data Portal icosdp
The data store icosdp provides datasets of the ICOS Data Portal.
This data store is provided by the xcube plugin xcube-icosdp.
You can install it using pip install xcube-icosdp.
The plugin currently supports the FLUXCOM-X-BASE products for carbon and water fluxes. To improve usability, the data is available through:
Native resolution via cloud-optimized access (spatial/temporal subsetting) via
open_dataPre-computed spatial & temporal aggregations via
preload_data
Data store parameters:
email: str- E-mail used when signing in at https://cpauth.icos-cp.eu/login/. This is only needed if the aggregated datasets want to be accessed viapreload_data.password: str- Password used when signing in at https://cpauth.icos-cp.eu/login/. This is only needed if the aggregated datasets want to be accessed viapreload_data.cache_store_id: str- The cache data store is a filesystem-based data store implemented in xcube, which is used to store the preloaded data.cache_store_params: dict- The available parameters can be viewed usingget_data_store_params_schema(cache_store_id).
Common parameters for opening xarray.Dataset instances:
flatten_time: bool- If enabled, combines the ‘time’ and ‘hour’ dimensions into a single datetime axis.
Common parameters for preloading xarray.Dataset instances:
agg_mode: str- Four aggregation modes are published in the ICOS FLUXCOM-X-BASE collection. One of"050_monthly","025_monthlycycle","025_daily","005_monthly".flatten_time: bool- If enabled, combines the ‘time’ and ‘hour’ dimensions into a single datetime axis. This option is available only whenagg_mode='025_monthlycycle'.target_format: str- Format of the preloaded dataset in the cache. One of"zarr"or"netcdf".chunks: tuple[int]- Chunk sizes for each dimension of the preloaded datasets; an iterable with length same as number of dimensions.
Sentinel Hub API
The data store sentinelhub provides the datasets of the
Sentinel Hub API.
This data store is provided by the xcube plugin xcube-sh.
You can install it using conda install -c conda-forge xcube-sh.
Data store parameters:
client_id: str- Sentinel Hub API client identifierclient_secret: str- Sentinel Hub API client secretapi_url: str- Sentinel Hub API URL. Defaults to'https://services.sentinel-hub.com'.oauth2_url: str- Sentinel Hub API authorisation URL. Defaults to'https://services.sentinel-hub.com/oauth'.enable_warnings: bool- Whether to output warnings. Defaults toFalse.error_policy: str- Policy for errors while requesting data. Defaults to'fail'.num_retries: int- Number of retries when requesting data fails. Defaults to200.retry_backoff_max: int- Defaults to40.retry_backoff_base: number- Defaults to1.001.
Common parameters for opening xarray.Dataset instances:
bbox: (float, float, float, float)- Bounding box in coordinate units ofcrs. Required.crs: str- Defaults to'WGS84'.time_range: (str, str)- Time range. Required.variable_names: list[str]- List of variable names. Defaults to all.variable_fill_values: list[float]- List of fill values according tovariable_namesvariable_sample_types: list[str]- List of sample types according tovariable_namesvariable_units: list[str]- List of sample units according tovariable_namestile_size: (int, int)- Defaults to(1000, 1000).spatial_res: float- Required.upsampling: str- Defaults to'NEAREST'.downsampling: str- Defaults to'NEAREST'.mosaicking_order: str- Defaults to'mostRecent'.time_period: str- Defaults to'1D'.time_tolerance: str- Defaults to'10M'.collection_id: str- Name of the collection.four_d: bool- Defaults toFalse.extra_search_params: dict- Extra search parameters passed to a catalogue query.max_cache_size: int- Maximum chunk cache size in bytes.
SpatioTemporal Asset Catalogs
Several data stores provide access to datasets from different SpatioTemporal Asset Catalogs.
These stores are provided by the xcube plugin xcube-stac. You can install it using conda install -c conda-forge xcube-stac.
stac
The stac data store retrieves datasets from a user-defined STAC API. It provides
access to items within a STAC catalog and exposes the data sources referenced by each
STAC item as an xr.Dataset.
Specific parameters for this store are:
url: str- URL to STAC catalog. Required.**store_params: Store parameters to configure the store used to access the data, which are the same as those used forhttpsands3stores. The hrefs in the STAC assets determines whether data is accessed viahttpsors3.
stac-xcube
The data store stac-xcube connects to STAC catalogs published on a xcube Server.
Specific parameters for this store are:
url: str- URL to STAC catalog. Required.**store_params: Store parameters to configure thes3store used to access the data.
stac-cdse and stac-cdse-ardc
The stac-cdse and stac-cdse-ardc data stores provide direct access to datasets
published by the CDSE STAC API.
To access EO data via S3 from CDSE, you must generate S3 credentials. These credentials are required during store initialization:
key: str- S3 key credential for CDSE data accesssecret: str- S3 secret credential for CDSE data access.
Differences between the two stores:
stac-cdse: Generates a unified dataset from a single CDSE STAC item (observational tile) with tailored data processing. Only items from the collections listed below are supported.stac-cdse-ardc: Generates 3D spatiotemporal analysis-ready data cubes (ARDCs) from multiple STAC items for the supported CDSE collections listed below.
Supported CDSE STAC collections:
stac-pc and stac-pc-ardc
The stac-pc and stac-pc-ardc stores function similarly to stac-cdse and
stac-cdse-ardc, but provide direct access to datasets published by the
Planetary Computer STAC API.
No parameters are required for initialization.
Currently supported collections:
Note
There are no common parameters for opening datasets with the stac data stores. As the available datasets are varying across a wide spectrum of datatypes no specific opening parameters can be named here. The stores delegate to the general xcube DataOpener which offers a variety of parameters depending on the datatype of the dataset.
Use the following function to access the parameters fitting for the dataset of interest:
open_schema = store.get_open_data_params_schema("data_id")
Zenodo zenodo
The data store zenodo provides access to datasets published on Zenodo.
This data store is provided by the xcube plugin xcube-zenodo.
You can install it using conda install -c conda-forge xcube-zenodo.
Data store parameters:
root: str- Zenodo record ID. Required.cache_store_id: str- Store ID of cache data store. Defaults tofile.cache_store_params: dict- Store parameters of a filesystem-based data store. Defaults to:{"root":"zenodo_cache","max_depth":10}.
Before opening a specific dataset in .zip format, it’s required to preload the data first. Preloading lets you create data requests ahead of time, which may sit in a queue before being processed. Once processed, the data is downloaded as zip files, unzipped, extracted to a cache, and prepared for use. After this, it can be accessed through the cache data store.
The preload parameters are:
blocking: bool- Switch to make the preloading process blocking or non-blocking. If True, the preloading process blocks the script. Defaults toTrue.silent: bool- Switch to visualize the preloading process. If False, the preloading progress will be visualized in a table. If True, the visualization will be suppressed. Defaults toTrue.
There are no common parameters for opening datasets with the xcube-zenodo store.
As the datasets uploaded on Zenodo are varying across a wide spectrum of datatypes
no specific opening parameters can be named here. xcube-zenodo delegates to the
general xcube DataOpener which offers a variety of open parameters depending on the
datatype of the dataset.
Use the following function to access the parameters fitting for the dataset of interest:
open_schema = store.get_open_data_params_schema("data_id")
Developing new data stores
Implementing the data store
New data stores can be developed by implementing the xcube DataStore interface for read-only data store, or the MutableDataStore interface for writable data stores, and should follow the xcube Data Store Conventions.
If a data store supports combinations of Python data types, external storages
types, and/or data formats it should consider the following design pattern:
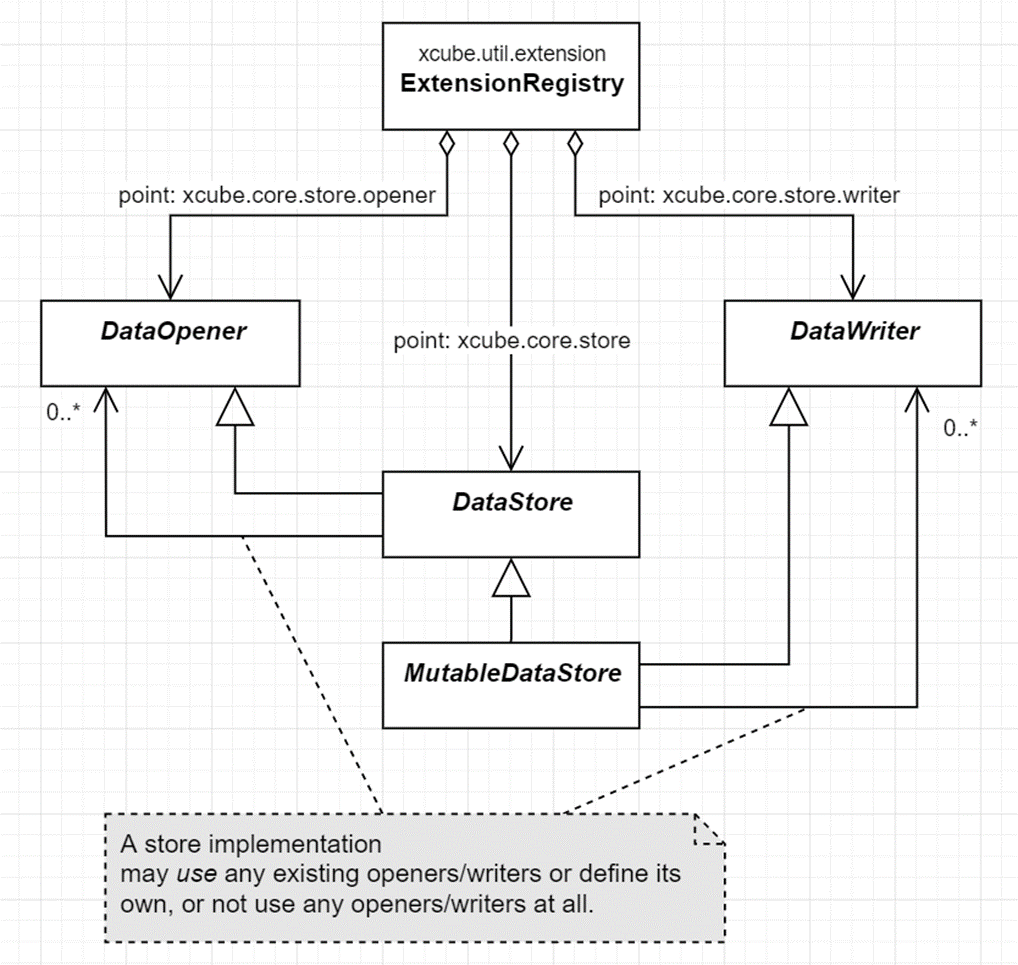
Here, we implement a dedicated DataOpener for a suitable combination of
supported Python data types, external storages types, and/or data formats.
The DataStore, which implements the DataOpener interface delegates
to specialized DataOpener implementations based on the open
parameters passed to the open_data() method. The same holds for the
DataWriter implementations for a MutableDataStore.
New data stores that are backed by some cloud-based data API can make use the xcube GenericZarrStore to implement the lazy fetching of data array chunks from the API.
Registering the data store
To register the new data store with xcube, it must be provided as
a Python package. Based on the package’s name there are to ways
to register it with xcube. If your package name matches the pattern
xcube_*, then you would need to provide a function init_plugin()
in the package’s plugin module (hence {package}.plugin.init_plugin()).
Alternatively, the package can have any name, but then it must register
a setuptools entry point in the slot “xcube_plugins”. In this case the
function init_plugin() can also be placed anywhere in your code.
If you use pyproject.toml:
[project.entry-points.xcube_plugins]
{your_name} = "{your_name}.plugin:init_plugin"
If you use setup.cfg:
[options.entry_points]
xcube_plugins =
{your_name} = {your_package}.plugin:init_plugin
If you use setup.py:
from setuptools import setup
setup(
# ...,
entry_points={
'xcube_plugins': [
'{your_name} = {your_package}.plugin:init_plugin',
]
}
)
The function init_plugin will be implemented as follows:
from xcube.constants import EXTENSION_POINT_DATA_OPENERS
from xcube.constants import EXTENSION_POINT_DATA_STORES
from xcube.constants import EXTENSION_POINT_DATA_WRITERS
from xcube.util import extension
def init_plugin(ext_registry: extension.ExtensionRegistry):
# register your DataStore extension
ext_registry.add_extension(
loader=extension.import_component(
'{your_package}.store:{YourStoreClass}'),
point=EXTENSION_POINT_DATA_STORES,
name="{your_store_id}",
description='{your store description}'
)
# register any extra DataOpener (EXTENSION_POINT_DATA_OPENERS)
# or DataWriter (EXTENSION_POINT_DATA_WRITERS) extensions (optional)
ext_registry.add_extension(
loader=extension.import_component(
'{your_package}.opener:{YourOpenerClass}'),
point=EXTENSION_POINT_DATA_OPENERS,
name="{your_opener_id}",
description="{your opener description}",
filename_extensions=[".j2k", ".zarr"], # adjust or leave empty
)